Oracle Cloud Infrastructure (OCI) Computeは、NVIDIA GPUを実装したベア・メタルや仮想マシン(VM)インスタンスに業界をリードするスケーラビリティをもたらし、メインストリームのグラフィックス、AI推論、AIトレーニング、デジタル・ツイン、およびHPCを実現します。
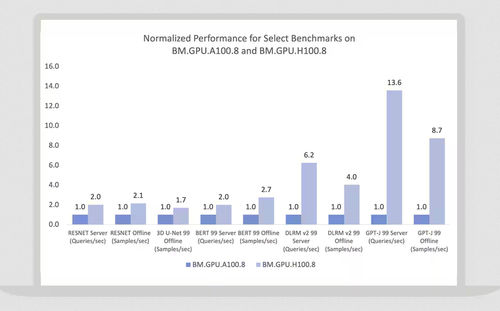
OCIは、NVIDIA GPUを搭載したベアメタル・インスタンスを提供する唯一の大手クラウド・プロバイダーであり、仮想化のオーバーヘッドを伴わない高いパフォーマンスを実現します。AIトレーニング時のチェックポイント処理では、オラクルのインスタンスはノード当たりで最大のローカル・ストレージ(61.44TB)を提供します。
高パフォーマンスなNVIDIA GPUのインスタンス
NVIDIA TensorコアGPU
OCIは、NVIDIA H100 Tensor Core GPU、L40S GPU、A100 Tensor Core GPU、A10 Tensor Core GPU、および旧世代のNVIDIA GPUを実装したベアメタルおよび仮想マシン・コンピュート・インスタンスに最高の価値とパフォーマンスを提供します。OCIでは、NVIDIA H200とBlackwell GPUを搭載したインスタンスの提供を予定しています。
NVIDIAスーパーチップ
OCIは、NVIDIA GH200 Grace Hopper Superchipを提供しており、LLM 推論用にGB200 Grace Blackwell Superchipを提供する予定です。
高パフォーマンスのクラスタ・ネットワーク
オラクルの超低レイテンシ・クラスタ・ネットワーキングは、リモート・ダイレクト・メモリ・アクセス(RDMA)をベースとし、マイクロ秒レベルのレイテンシを実現します。
VM、ベアメタル・インスタンス、Kubernetesクラスタに導入
VMインスタンス
VM向けには、NVIDIAのHopper、Ampere、および以前のGPUアーキテクチャから、1~4コア、VMあたり16~64 GBのGPUメモリ、および最大48 Gb/secのネットワーク帯域幅を選択できます。
ベアメタル・インスタンス
NVIDIAのBlackwell、Hopper、またはAmpere Superchipsと、ノードあたり640 GBのGPUメモリを持つGPUを使用したベアメタル・インスタンスでOCI Superclusterを使用します。
Kubernetesによるオーケストレーション
マネージドKubernetes、サービス・メッシュ、コンテナ・レジストリを活用し、コンテナを使用してAIおよび機械学習(ML)のトレーニングや推論をオーケストレーションします。