
- Company
- Products
- Catalogs
- News & Trends
- Exhibitions
Management software engineeringdatabasequality

Add to favorites
Compare this product
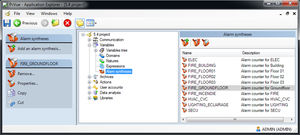
Characteristics
- Function
- management, engineering, database, quality
- Applications
- industrial
- Type
- real-time
- Other characteristics
- high-performance
Description
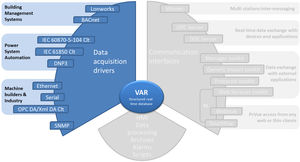
An industrial data platform designed to help you collect, store, and analyze all your organization’s process
data. The Enterprise Historian is a NoSQL time series database. That simply means it is built to specifically store
time series data and does not rely on an SQL database to do so.
Every tag you choose to store in the Enterprise Historian can contain the following data:
• Tag name
• 100+ meta data properties (engineering units, descriptions, limits, and more)
• Timestamps
• Values (booleans, floats, integers, strings, etc)
• Quality score
Imagine the amount of data that can be produced if you have 5,000 tags sending values every second.
What if it was 50,000 tags, or even 500,000?
That’s exactly why Enterprise Historian chooses not to use SQL, its just too much data for a relational database.
specialty time series data.
No database management required
Provides loss-less compression
Performance unaffected by database size
Highly compressed storage
No additional database licensing costs
Accept SQL queries
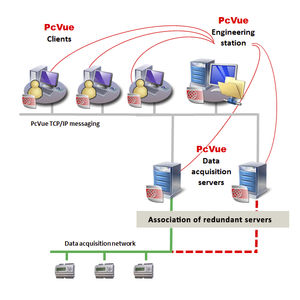
When you deploy Enterprise Historian, you organize your tags into DataSets. A DataSet is a collection of
sensors, or tags, that you choose to group together. Since you license the Historian only by tag count, you
can create as many DataSets as you need.
Within each DataSet, the Enterprise Historian writes to a Historical DataBase file, or HDB file for short. The
HDB contains all the tag names and records the timestamp for every value change as well as its quality
score. You can also associate properties to each tag allowing you to store descriptions, engineering units,
limits, and more. Typically, a new HDB file is created daily.
Catalogs
No catalogs are available for this product.
See all of ARC Informatique‘s catalogsOther ARC Informatique products
Products & Technology





Related Searches
- Automation software solution
- Management software solution
- Analysis software solution
- Process software solution
- Windows software solution
- Control software solution
- Computer-aided design software
- Real-time software solution
- Design software solution
- 3D software solution
- Monitoring software solution
- Interface software
- Measurement software
- Industrial software solution
- Quality software
- Development software
- Network software solution
- Machine software
- Engineering software
- EDM software
*Prices are pre-tax. They exclude delivery charges and customs duties and do not include additional charges for installation or activation options. Prices are indicative only and may vary by country, with changes to the cost of raw materials and exchange rates.