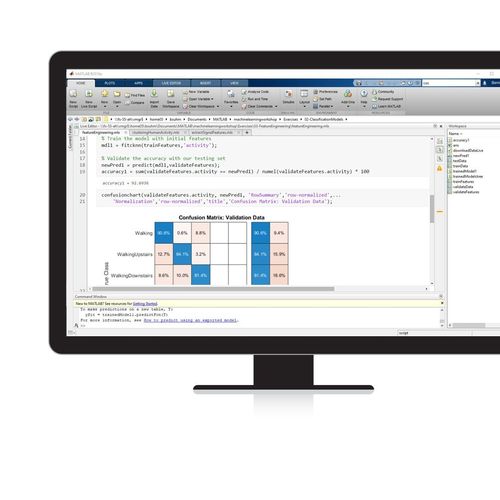
Statistics and Machine Learning Toolbox™ provides functions and apps to describe, analyze, and model data. You can use descriptive statistics, visualizations, and clustering for exploratory data analysis; fit probability distributions to data; generate random numbers for Monte Carlo simulations, and perform hypothesis tests. Regression and classification algorithms let you draw inferences from data and build predictive models either interactively, using the Classification and Regression Learner apps, or programmatically, using AutoML.
For multidimensional data analysis and feature extraction, the toolbox provides principal component analysis (PCA), regularization, dimensionality reduction, and feature selection methods that let you identify variables with the best predictive power.
The toolbox provides supervised, semi-supervised, and unsupervised machine learning algorithms, including support vector machines (SVMs), boosted decision trees, k-means, and other clustering methods. You can apply interpretability techniques such as partial dependence plots and LIME, and automatically generate C/C++ code for embedded deployment. Many toolbox algorithms can be used on data sets that are too big to be stored in memory.